SQL增删查改
1. 在单一表格检索数据
SELECT 语句
SELECT用于从数据库中选取数据,返回的表称为结果集
1 | -- SELECT 语法 |
column 为选取的列字段名,TABLE_NAME为查询的表名称
选择子句SELECT Clause
可在选择子句中嵌套数学表达式,特定值,文本;

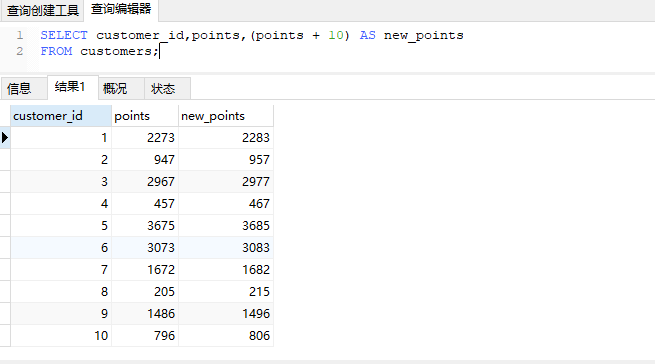
如对于表customer,执行sql语句
1 | SELECT customer_id,points,(points + 10) AS new_points |
返回结果集
在这个案例中 返回了新的一列“new_points”,它的结果是每一行数据points列值+10
使用AS得到了一个新的列别名
WHERE 子句
WHERE子句用于过滤记录,在一些场景中一张表里可能有成百上千万行数据,针对某一次查询如果返回所有的数据会对数据库造成很大的压力;
1 | -- WHERE子句 语法 |
condition为表达式
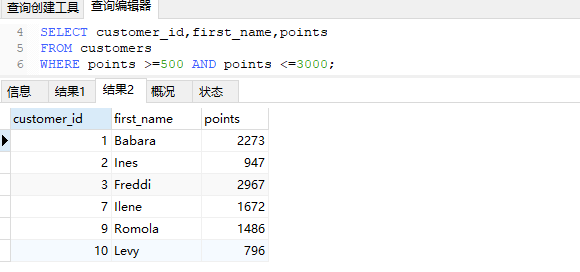
还是针对上面的customers表,执行
1 | SELECT customer_id,first_name,points |
这个sql语句返回了所有points列大于等于500的数据
AND NOT OR 逻辑运算
这三个运算符号与字面意思相同,用于处理where语句中多条表达式“或”“与”“取反”逻辑
如我们需要得到points值在区间[500,3000]中的数据,可以像这样写
1 | SELECT customer_id,first_name,points |
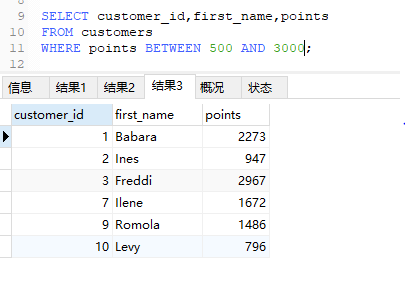
对于AND逻辑,sql有一个简化的语法,使用BETWEENK操作符,它用于选取介于两个值之间的数据范围
1 | SELECT customer_id,first_name,points |
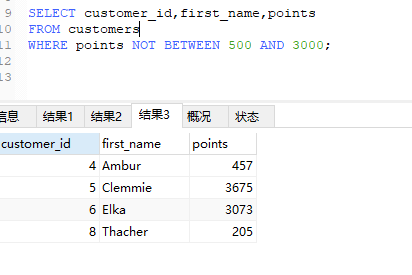
接下来,选取除了这个区间以外的数据,修改一下上面的sql语句
1 | SELECT customer_id,first_name,points |
现在记住,NOT用于表达式中取反
对于字符串检索 (LIKE,REGEXP)
在真实情境中不可能每一列都是数字或日期,如first_name;在sql操作中对字符串进行寻找是很常见的操作
稍有年头的LIKE操作符可以帮我们完成这个任务,它就像正则表达式青春版,可以完成一些简单的工作
对于了解使用过正则表达式的开发者,只需记住 “%””_”分别占位 “任意个字符” “一个字符” 即可
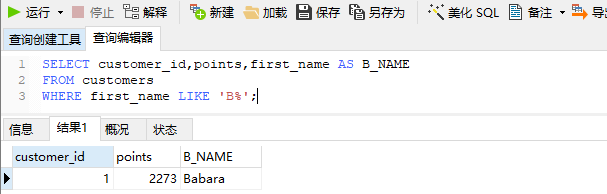
现在,我们将要检索first_name列值以b开头的数据,这样写
1 | SELECT customer_id,points,first_name AS B_NAME |
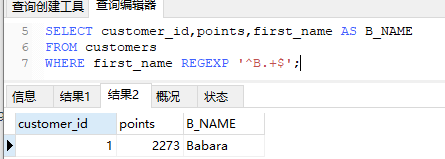
sql也支持正则表达式,使用REGEXP操作符进行
1 | SELECT customer_id,points,first_name AS B_NAME |
对结果集进行排序 (ORDER BY)
ORDER BY 关键字用于对结果集进行排序。
1 | SELECT column1, column2, ... |
ORDER BY 后面紧跟进行排序的列字段,DESC为降序,默认使用升序
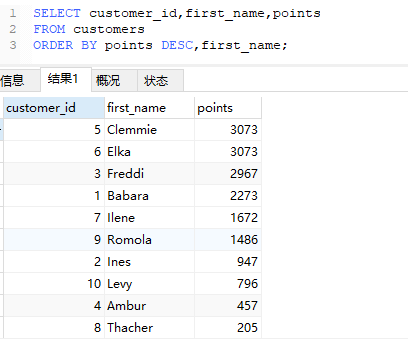
1 | SELECT customer_id,first_name,points |
观察id为5和6这两行数据;根据ORDER BY使用的规则,先对points进行降序,当points一样的时候;
使用了后一个规则,对first_name进行了升序排序
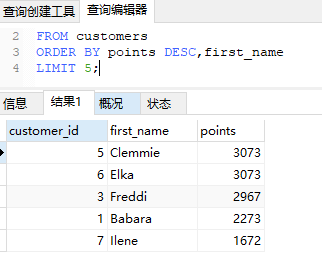
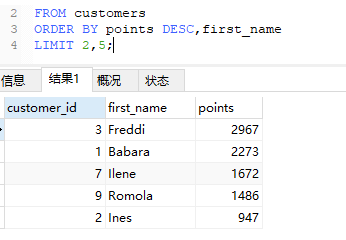
使用LIMIT关键词限定查询数据量
修改上面的sql语句
1 | SELECT customer_id,first_name,points |
同时可以为LIMIT设置一个偏移量,这对一些分页操作的查询是很有用的技巧
1 | SELECT customer_id,first_name,points |
2为偏移量,查询5条数据
2. 在多表之间检索数据
单表是满足不了大部分业务需求的,很多时候采用多表关联来解决存储问题,如对于该表

orders是一张“订单表”,其中order_id字段为主键与表order_items中的同名字段相关联;orders.order_id也称之为“外键”
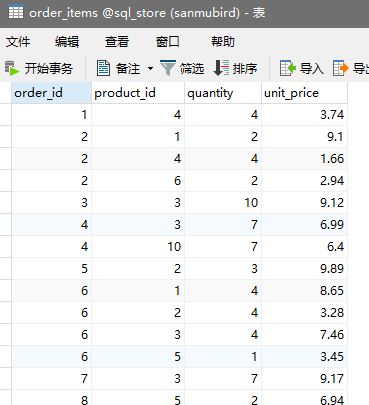
当我们查询orders的时候,想要同时得到产品id(product_id),它在另外一张表中,这个时候怎么操作?使用JOIN连接关键词
1 | SELECT column1, column2, ... |
codition为连接条件,用于指定连接方式
1 | SELECT o.order_id,oi.product_id |
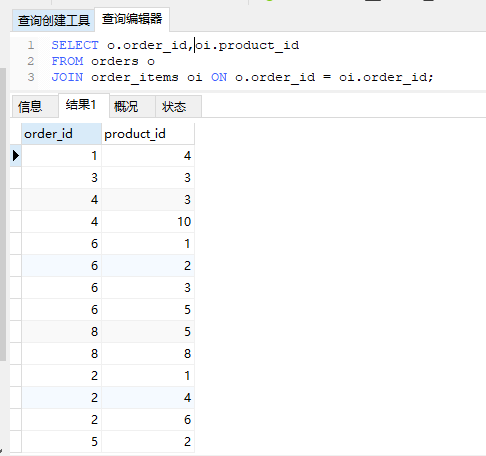
在sql语句中 o,oi 为表的别名,而SELECT查询列的o.order_id是为指定order_id是哪张表中的字段(原因是orders,order_items中
都有order_id这个字段)
外连接
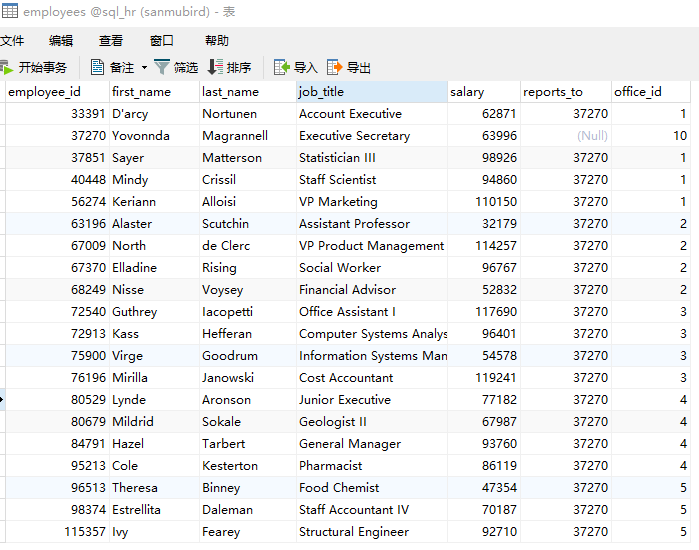
什么是外连接?在清楚这个概念之前先引入一张新的示例表
很明显这张表用于管理某个公司中的员工,其中reports_to列指定了他的上级(汇报人员;而reports_to对应的employee_id
现在我们要查找所有人员以及他的上级id
利用前面的概念很轻松的写出查询
1 | USE sql_hr; |
(注意,表自己与自己连接,称之为自连接SelfJoin)
仔细看结果集似乎有点不对,我们期望得到所有人员以及他的管理员;但貌似少了一行
也就是first_name为Yovonnda的数据,这是为什么呢?往回翻一下表,发现Yovonnda的reports_to列为NULL
没什么好奇怪的,他没有上级,这可能是公司的CEO
要想得到正确的结果,就得了解下所谓内连接与外连接的差别了
上文所提到所使用的JOIN语句都默认使用的内连接,即
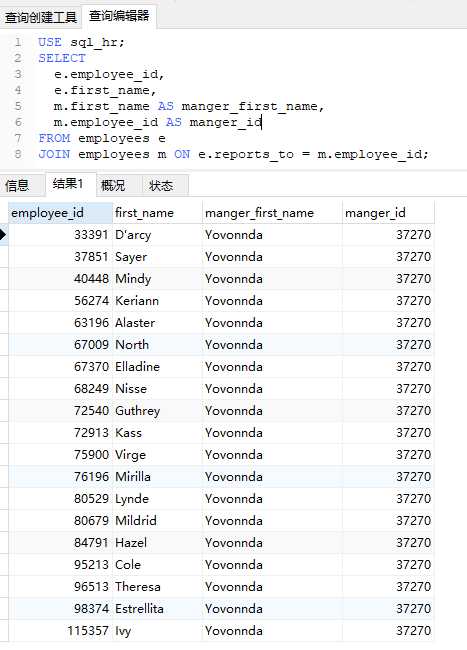

以某种条件进行连接的,两张表之间的交集
既然Yovonnda的reports_id为NULL,也就没有交集,自然也查询不到他的信息;
我们可以使用外连接来修复这个错误
1 | SELECT o.order_id,oi.product_id |
修改一下sql语句
1 | USE sql_hr; |
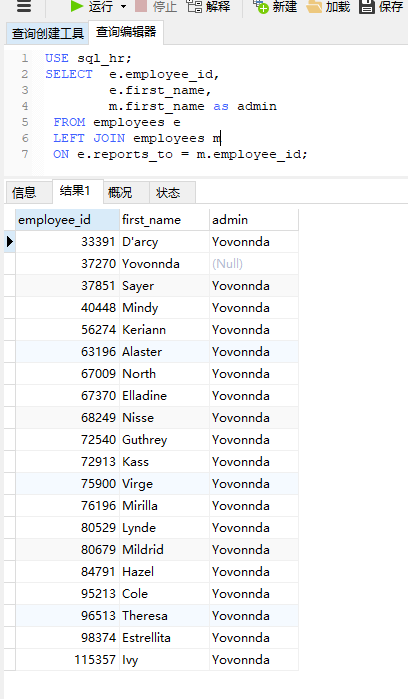
ok,现在的结果集是我们期望得到的了;可以看到外连接与内连接的差别只是多了个LEFT,它指的是左表,在这个例子中是FROM的
employess,它将左表中无法与右表建立连接的记录也返回;在大多数时候为了sql语句清晰,我们只使用left而少用right
3. 插入,更新,删除数据
插入 (INSERT INTO)
语法:
第一种方式无需提供插入的列字段名,只需提供值
1 | INSERT INTO table_name |
也可以这样
1 | INSERT INTO table_name (column1,column2,column3,...) |
尝试往customers表里插入一名新的客人,执行
1 | USE sql_store; |
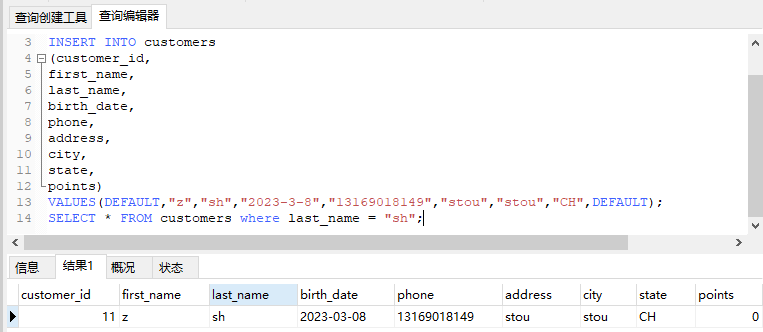
DEFAULT为缺省值,即使用字段中定义的自增或默认值
也可以同时插入多行
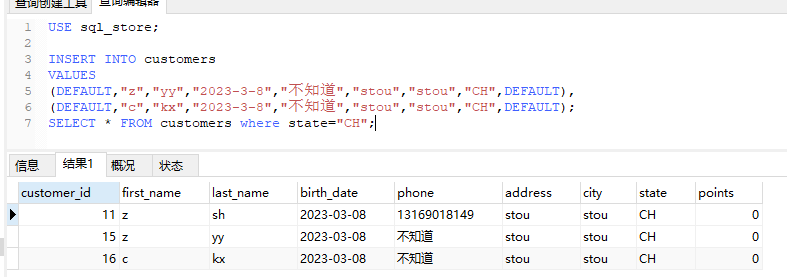
插入分层行 (LAST_INSERT_ID函数)
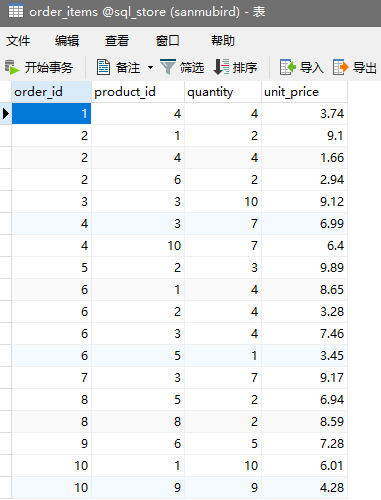
如图所展示的两张表 “orders” “order_items” ,他们使用order_id作为外键进行连接,母表orders一行记录可能对应子表order_items多条数据; 在插入的时候不止要操作orders表,同时还要插入order_items(订单产品信息)
在写sql语句的时候会遇到一个问题,order_id作为自增列,为了防止重复在插入时无法指定该字段的值;而往子订单里插入数据的时候又需要该字段作为索引,使用LAST_INSERT_ID()来解决问题
LAST_INSERT_ID()是mysql内置的功能函数,它会返回上一次创建的自增值
1 | INSERT INTO orders |
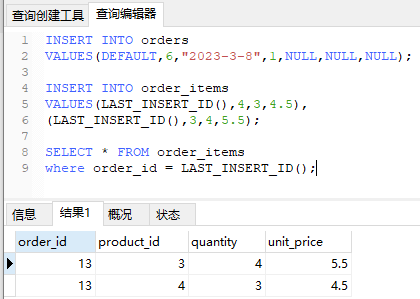
复制表数据 (子查询)
有时候需要将表中所有或某一部分数据拷贝到另一张表,一条条记录insert是效率极低的
1 | CREATE TABLE orders_copy |
该查询会创建一张新的表”orders_copy”,并导入所有orders表中的数据;CREATE TABLE 后紧跟着的SELECT 称之为子查询
充分利用该特性可以完成许多骚操作,例如
1 | CREATE TABLE orders_copy2 |
该查询会得到一张新的表,里面记录了2019-1-1之前的订单数据;值得注意的是,该方式会忽略所有列属性
复制出来的表,其中order_id并没有被标注为主键,也没有自增属性
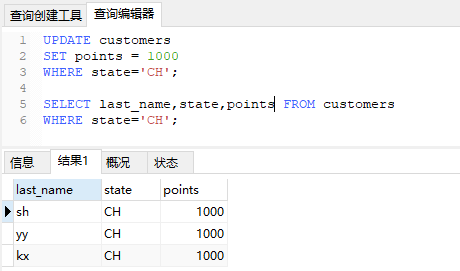
更新表数据 (UPDATE)
使用UPDATE来更新数据
1 | UPDATE table_name |
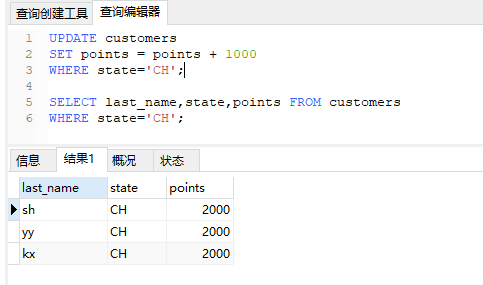
例如,将customer中,所有state=CH的数据points列更改为1000
1 | UPDATE customers |
其中也可以嵌套数学表达式,例如为所有CH的客户加1000积分
删除表数据 (DELETE)
DELETE语句用于删除数据
1 | DELETE FROM table_name |
where condition作为缺省值出现,如果不填写会默认删除整张表的数据
本文标题:SQL增删查改
文章作者:meteor
发布时间:2023-03-07
最后更新:2023-03-07
原始链接:http://blog.zsenhe.com/2023/03/07/SQL%E5%A2%9E%E5%88%A0%E6%9F%A5%E6%94%B9/
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 CN 许可协议。转载请注明出处!
分享