XPath与XPathParse XPath mybatis在初始化过程中处理MybatisConfig.xml以及映射文件时,使用的是DOM解析方式,并结合XPath(javax.xml.xpath包下)对配置文件进行解析,XPath对XML文件来说就相当于SQL语言之于数据库。
XPath使用路径表达式来选取XML文档中指定的节点或节点集合,对于XPath的语法需要简单了解一下
例如对于以下xml文件
1 2 3 4 5 <?xml version="1.0" encoding="UTF-8" ?> <books > <book id ="1001" year ="1955" > <name > 神雕侠侣</name > <author > 金庸</author > </book > <book id ="1002" year ="1986" > <name > 天龙八部</name > <author > 金庸</author > </book > </books >
查找所有书籍的表达式是 “//book”,查找作者为 ‘金庸’ 的所有图书需要制定的值,得到表达式 “//book[author=’金庸’]”,再加一个筛选条件,我们需要得到 所有在1955年之后(不包括1995)发行的书,这就需要得到book的属性节点year。此时我们的表达式长这样:
//book[author=’金庸’][@year>1955]
得到了所有符合条件的节点后,我们需要的是书的名字,于是定位到book节点下的
//book[author=’金庸’][@year>1955]/name/text()
如上所述,text()用于匹配节点的文本,通过该表达式的筛选,我们得到了
完整的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 public class XPathTest { public static void main (String[] args) { DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance(); documentBuilderFactory.setValidating(true ); documentBuilderFactory.setNamespaceAware(true ); documentBuilderFactory.setIgnoringComments(true ); documentBuilderFactory.setIgnoringElementContentWhitespace(false ); documentBuilderFactory.setCoalescing(false ); documentBuilderFactory.setExpandEntityReferences(true ); try { DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder(); documentBuilder.setErrorHandler(new ErrorHandler () { @Override public void warning (SAXParseException exception) throws SAXException { System.out.println("warning: " +exception.getMessage()); } @Override public void error (SAXParseException exception) throws SAXException { System.out.println("error: " +exception.getMessage()); } @Override public void fatalError (SAXParseException exception) throws SAXException { System.out.println("fatal: " +exception.getMessage()); } }); Document document = documentBuilder.parse(new FileInputStream (new File ("bookdata.xml" ))); XPathFactory xPathFactory = XPathFactory.newInstance(); XPath xPath = xPathFactory.newXPath(); XPathExpression expression = xPath.compile("//book[author='金庸'][@year>1955]/name/text()" ); Object evaluate = expression.evaluate(document, XPathConstants.NODESET); NodeList nodeList = (NodeList) evaluate; for (int i = 0 ; i < nodeList.getLength(); i++) { System.out.println(nodeList.item(i).getNodeValue()); } } catch (ParserConfigurationException e) { throw new RuntimeException (e); } catch (IOException e) { throw new RuntimeException (e); } catch (SAXException e) { throw new RuntimeException (e); } catch (XPathExpressionException e) { throw new RuntimeException (e); } } }
注意这一行代码:
Object evaluate = expression.evaluate(document, XPathConstants.NODESET);
evaluate的第二个参数接受一个枚举类型,他的意义是指定Xpath表达式查找的结果类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 public class XPathConstants { private XPathConstants () { } public static final QName NUMBER = new QName ("http://www.w3.org/1999/XSL/Transform" , "NUMBER" ); public static final QName STRING = new QName ("http://www.w3.org/1999/XSL/Transform" , "STRING" ); public static final QName BOOLEAN = new QName ("http://www.w3.org/1999/XSL/Transform" , "BOOLEAN" ); public static final QName NODESET = new QName ("http://www.w3.org/1999/XSL/Transform" , "NODESET" ); public static final QName NODE = new QName ("http://www.w3.org/1999/XSL/Transform" , "NODE" ); public static final String DOM_OBJECT_MODEL = "http://java.sun.com/jaxp/xpath/dom" ; }
另外,如果XPath表达式只使用一次,可以跳过编译步骤直接调用Xpath对象的evaulate方法。但如果是重复多次的调用,编译后性能更佳。
XPathParse Mybatis提供的XPathParser类封装了上文提到的XPath,Document和EntityResolver
XPathParser的字段如下:
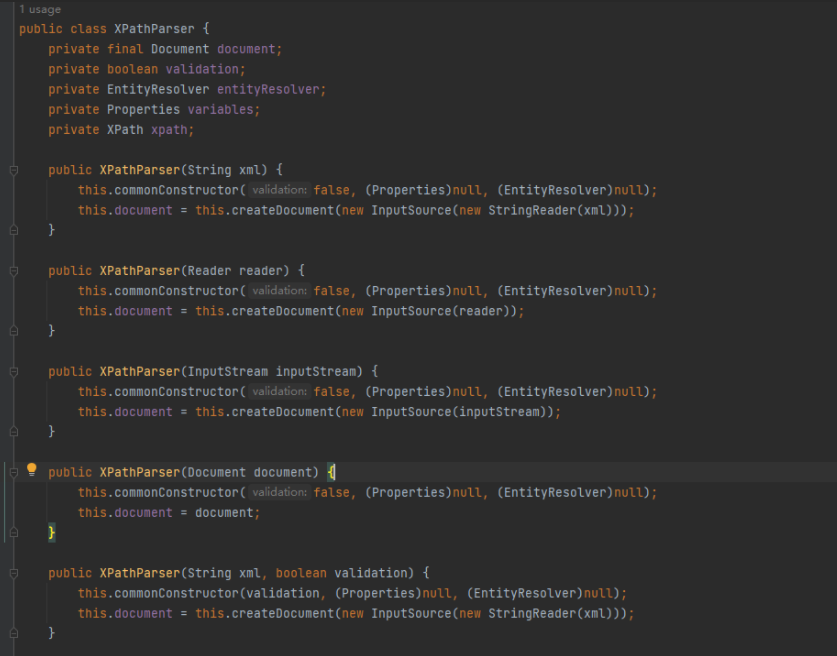
1 2 3 4 5 6 7 8 public class XPathParser (){ private final Document document; private boolean validation; private EntityResolver entityResolver; private Properties variables; private XPath xpath; ..... }
默认情况下,对XML文档进行验证时,会根据XML文档开始位置加载对应的DTD文件
DTD文件为对XML的约束,可参考 DTD 教程 | 菜鸟教程
如果解析mybatis-config文件时,默认联网加载 http://mybatis.org/dtd/mybatis-3-config.dtd 这个文档,当网络比较慢时会导致验证过程缓慢。在开发中往往会设置EntityResolver接口对象加载本地的DTD文件,从而避免联网加载。
XMLMapperEntityResolver是Mybatis提供的EntityResolver接口的实现类,该接口的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 public class XMLMapperEntityResolver implements EntityResolver { private static final String IBATIS_CONFIG_SYSTEM = "ibatis-3-config.dtd" ; private static final String IBATIS_MAPPER_SYSTEM = "ibatis-3-mapper.dtd" ; private static final String MYBATIS_CONFIG_SYSTEM = "mybatis-3-config.dtd" ; private static final String MYBATIS_MAPPER_SYSTEM = "mybatis-3-mapper.dtd" ; private static final String MYBATIS_CONFIG_DTD = "org/apache/ibatis/builder/xml/mybatis-3-config.dtd" ; private static final String MYBATIS_MAPPER_DTD = "org/apache/ibatis/builder/xml/mybatis-3-mapper.dtd" ; public XMLMapperEntityResolver () { } public InputSource resolveEntity (String publicId, String systemId) throws SAXException { try { if (systemId != null ) { String lowerCaseSystemId = systemId.toLowerCase(Locale.ENGLISH); if (lowerCaseSystemId.contains("mybatis-3-config.dtd" ) || lowerCaseSystemId.contains("ibatis-3-config.dtd" )) { return this .getInputSource("org/apache/ibatis/builder/xml/mybatis-3-config.dtd" , publicId, systemId); } if (lowerCaseSystemId.contains("mybatis-3-mapper.dtd" ) || lowerCaseSystemId.contains("ibatis-3-mapper.dtd" )) { return this .getInputSource("org/apache/ibatis/builder/xml/mybatis-3-mapper.dtd" , publicId, systemId); } } return null ; } catch (Exception var4) { throw new SAXException (var4.toString()); } } private InputSource getInputSource (String path, String publicId, String systemId) { InputSource source = null ; if (path != null ) { try { InputStream in = Resources.getResourceAsStream(path); source = new InputSource (in); source.setPublicId(publicId); source.setSystemId(systemId); } catch (IOException var6) { } } return source; } }
回到XPathParser对象,先看每个构造方法中都调用的createDocument(InputSource)方法,在调用该方法之前,会先调用commonConstructor()完成初始化
具体实现如下:
可以看到,createDocument的对象即是我们创建DocumentBuilder对象的封装。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 private Document createDocument (InputSource inputSource) { try { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); factory.setFeature("http://javax.xml.XMLConstants/feature/secure-processing" , true ); factory.setValidating(this .validation); factory.setNamespaceAware(false ); factory.setIgnoringComments(true ); factory.setIgnoringElementContentWhitespace(false ); factory.setCoalescing(false ); factory.setExpandEntityReferences(true ); DocumentBuilder builder = factory.newDocumentBuilder(); builder.setEntityResolver(this .entityResolver); builder.setErrorHandler(new ErrorHandler () { public void error (SAXParseException exception) throws SAXException { throw exception; } public void fatalError (SAXParseException exception) throws SAXException { throw exception; } public void warning (SAXParseException exception) throws SAXException { } }); return builder.parse(inputSource); } catch (Exception var4) { throw new BuilderException ("Error creating document instance. Cause: " + var4, var4); } } private void commonConstructor (boolean validation, Properties variables, EntityResolver entityResolver) { this .validation = validation; this .entityResolver = entityResolver; this .variables = variables; XPathFactory factory = XPathFactory.newInstance(); this .xpath = factory.newXPath(); }
往下看这个类,他提供了一系列的eval*()方法用于解析boolean,shor,string等不同数据类型。他通过调用前面介绍的XPath.evaluate()方法来查找指定路径的节点或数学,并进行相应的类型转换。
值得注意的是其中的evalString()方法,其中会调用PropertyParser.parse()方法处理节点中相应的默认值,实现如下
1 2 3 4 public String evalString (Object root, String expression) { String result = (String)this .evaluate(expression, root, XPathConstants.STRING); return PropertyParser.parse(result, this .variables); }
接着往下分析,打开PropertyParser类的实现
1 2 3 4 5 6 7 8 9 10 private static final String KEY_PREFIX = "org.apache.ibatis.parsing.PropertyParser." ;public static final String KEY_ENABLE_DEFAULT_VALUE = "org.apache.ibatis.parsing.PropertyParser.enable-default-value" ;public static final String KEY_DEFAULT_VALUE_SEPARATOR = "org.apache.ibatis.parsing.PropertyParser.default-value-separator" ;private static final String ENABLE_DEFAULT_VALUE = "false" ; private static final String DEFAULT_VALUE_SEPARATOR = ":" ; private PropertyParser () {}
PropertyParser. parse()方法中会创建 GenericTokenParser 解析器,并将默认值的处理委托给GenericTokenParser.parse()方法,实现如下
1 2 3 4 5 public static String parse (String string, Properties variables) { VariableTokenHandler handler = new VariableTokenHandler (variables); GenericTokenParser parser = new GenericTokenParser ("${" , "}" , handler); return parser.parse(string); }
GenericTokenParser是一个占位符解析类,它的字段解释如下:
1 2 3 4 5 6 public class GenericTokenParser { private final String openToken; private final String closeToken; private final TokenHandler handler; .... }
GenericTokenParser.parser()的逻辑也并不复杂,它将顺序查找openToken和closeToken,解析得到占位符的字面值,并将其交给传入的TokenHandler处理,然后将解析结果重新拼装成字符串返回。它的流程实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 public String parse (String text) { if (text != null && !text.isEmpty()) { int start = text.indexOf(this .openToken); if (start == -1 ) { return text; } else { char [] src = text.toCharArray(); int offset = 0 ; StringBuilder builder = new StringBuilder (); StringBuilder expression = null ; do { if (start > 0 && src[start - 1 ] == '\\' ) { builder.append(src, offset, start - offset - 1 ).append(this .openToken); offset = start + this .openToken.length(); } else { if (expression == null ) { expression = new StringBuilder (); } else { expression.setLength(0 ); } builder.append(src, offset, start - offset); offset = start + this .openToken.length(); int end; for (end = text.indexOf(this .closeToken, offset); end > -1 ; end = text.indexOf(this .closeToken, offset)) { if (end <= offset || src[end - 1 ] != '\\' ) { expression.append(src, offset, end - offset); break ; } expression.append(src, offset, end - offset - 1 ).append(this .closeToken); offset = end + this .closeToken.length(); } if (end == -1 ) { builder.append(src, start, src.length - start); offset = src.length; } else { builder.append(this .handler.handleToken(expression.toString())); offset = end + this .closeToken.length(); } } start = text.indexOf(this .openToken, offset); } while (start > -1 ); if (offset < src.length) { builder.append(src, offset, src.length - offset); } return builder.toString(); } } else { return "" ; } }
占位符的字面值由TokenHandler接口实现进行解析,TokenHandler接口有四个实现。
再回来看PropertyParser.parse()方法
1 2 3 private final Properties variables; private final boolean enableDefaultValue; private final String defaultValueSeparator;
VariableTokenHandler实现了TokenHandler接口中的handlerToken()方法,该实现首先会按照defaultValueSpearator字段对整个占位符进行切割,得到占位符的名称和默认值,按照名称查找对应的值,如不存在且默认值功能开启,则返回默认值。其中代码实现并不复杂,就不贴上来了
回到对XPathParser的分析,XPathParser.evalNode()返回值类型是XNode,它对org.w3c.dom.Node对象做了封装和解析,其字段含义如下:
1 2 3 4 5 6 7 8 public class XNode { private final Node node; private final String name; private final String body; private final Properties attributes; private final Properties variables; private final XPathParser xpathParser; }
XNode的构造函数中调用了它的parseAttributes()和parseBody()方法解析org.w3c.dom.Node对象中的信息,初始化attributes集合和body字段,过程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private Properties parseAttributes (Node n) { Properties attributes = new Properties (); NamedNodeMap attributeNodes = n.getAttributes(); if (attributeNodes != null ) { for (int i = 0 ; i < attributeNodes.getLength(); ++i) { Node attribute = attributeNodes.item(i); String value = PropertyParser.parse(attribute.getNodeValue(), this .variables); attributes.put(attribute.getNodeName(), value); } } return attributes; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 private String parseBody (Node node) { String data = this .getBodyData(node); if (data == null ) { NodeList children = node.getChildNodes(); for (int i = 0 ; i < children.getLength(); ++i) { Node child = children.item(i); data = this .getBodyData(child); if (data != null ) { break ; } } } return data; } private String getBodyData (Node child) { if (child.getNodeType() != 4 && child.getNodeType() != 3 ) { return null ; } else { String data = ((CharacterData)child).getData(); return PropertyParser.parse(data, this .variables); } }
到此,让我们玩一下XPathParser吧! 还记得我们之前获取1955年之后发行的书步骤吗,现在可以简化成如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class XPathParserTest { public static void main (String[] args) { try { XPathParser xPathParser = new XPathParser (new FileInputStream (new File ("bookdata.xml" ))); List<XNode> xNodes = xPathParser.evalNodes("//book[@year>1955]" ); for (XNode xNode : xNodes) { String id = xNode.getStringAttribute("id" ); XNode nameNode = xNode.evalNode("//name" ); XNode authorNode = xNode.evalNode("//author" ); System.out.println(id+":" +nameNode.getStringBody()+"/" +authorNode.getStringBody()); } } catch (FileNotFoundException e) { throw new RuntimeException (e); } } }
XNode中提供了多种get*()方法获取所需的节点信息,这些信息来源于attribute,body,node字段;也可以像上面这样通过eval*()配合XPath表达式来取得信息,需要注意的是,eval*中的上下文节点为当前Xnode对象的node字段。
参考资料 - 《MyBatis技术内幕》